|
|
You are here: Foswiki>Development Web>InternationalisationEnhancements>LocalizationFramework>UnicodeSupport>UnicodeProblemsAndSolutionCandidates (17 May 2015, CrawfordCurrie)Edit Attach
Problems with Unicode and Solution Candidates
See UseUTF8 instead.
The Task
Write a Perl programm that prints to STDOUT all its command line arguments and checks for each argument if there is an uppercase letter, immediately followed by one or more lowercase letters, immediately followed by an uppercase letter (Ul+U for short).A Warning
I'm not a Perl expert. The following experiments show the result für Perl v5.8.8. I do not claim, that my interpretations are correct. And I do not claim that the hints below help to solve the problem(s). The only thing I know: this hints helped to solve all my problems I had with unicode and Perl.1st Attempt
Experiments
#!/usr/bin/perl
use strict; use warnings;
my $regex = qr/ [[:upper:]] [[:lower:]]+ [[:upper:]] /x;
foreach my $arg (@ARGV) {
print "Argument: '$arg'\n";
print 'Ul+U ',($arg=~m/$regex/)?'':'not ',"found \n";
}

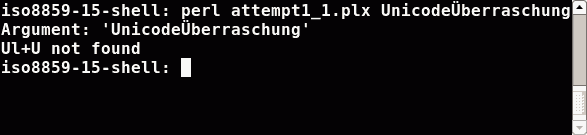
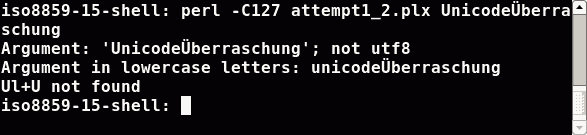
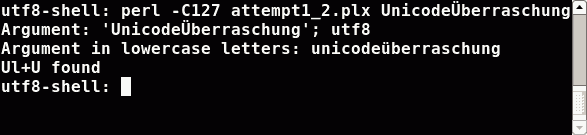
 This was not the expected result, because Ü is an uppercase letter (the lowercase
counterpart ist called ü; and for the sake of completeness: Überraschung means surprise).
To see what went wrong, we do two things. We tell Perl to write out alle the strings in the right encoding
(that is the encoding of the shell) and we ask Perl to convert the strings to lowercase letters:
This was not the expected result, because Ü is an uppercase letter (the lowercase
counterpart ist called ü; and for the sake of completeness: Überraschung means surprise).
To see what went wrong, we do two things. We tell Perl to write out alle the strings in the right encoding
(that is the encoding of the shell) and we ask Perl to convert the strings to lowercase letters:
#!/usr/bin/perl
use strict; use warnings;
use open IO => ':locale';
my $regex = qr/ [[:upper:]] [[:lower:]]+ [[:upper:]] /x;
foreach my $arg (@ARGV) {
print "Argument: '$arg'; ",utf8::is_utf8($arg)?'':'not ',"utf8\n";
print "Argument in lowercase letters: ",lc($arg),"\n";
print 'Ul+U ',($arg=~m/$regex/)?'':'not ',"found \n";
}


My Conclusions
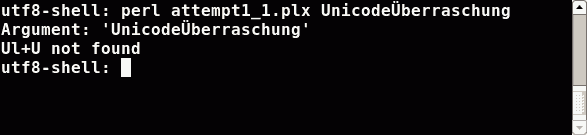
In the utf8 shell Perl didn't know (and has no chance to know) the bytes55 6e 69 63 6f 64 65 c3 9c 62 65 72 72 61 73 63 68 75 6e 67 0a coming in as first argument
were Unicode characters (utf8 encoded). Perl guessed the encoding and took some one byte encoding. It interpreted the byte c3 as one character (that one with tilde A).
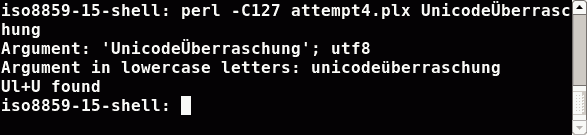
In the iso8859-15 shell Perl got the bytes 55 6e 69 63 6f 64 65 dc 62 65 72 72 61 73 63 68 75 6e 67 0a. Perl guessed some one byte encoding
and so the output is right. But the guessed encoding doesn't know about the letter Ü as an uppercase letter. Hence character classes don't work in this case.
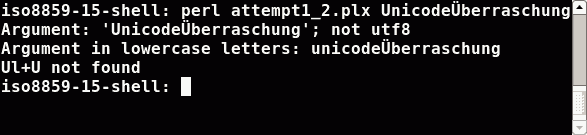
2nd Attempt
We have to tell Perl the encoding of our data (in our case the command line arguments). So let's do the same test again, only with one magic difference: telling Perl: our data is utf8 encoded if there are any hints in the LC_… variables. We do this, with the option '-C':

My Conclusions
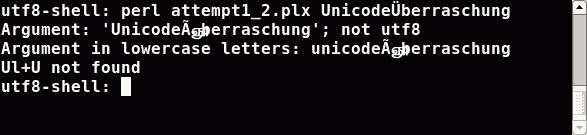
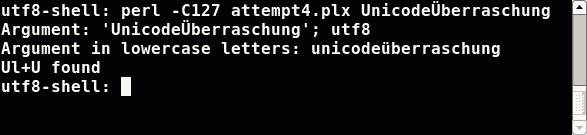
For the utf8 shell we are done. Everything works as expected. Perl sees my LC_ALL environment variable finds the utf8 string inside and sets the encoding for the command line arguments right. But in the iso8859-15 shell we have a problem. Perl has no hints for utf8 encoding in my LC_ALL environment variable. Perl chooses/guesses the same one-byte encoding as in the 1st attempt. Therefore the results are the same.3rd Attempt: Poor man's solution
In the non-utf-8 shell we have to force Perl to convert all the input to unicode (because Perl works best, when all the internal strings are encoded utf8). If we have no idea in what flavor/encoding the data comes in (because we do not know the shell encoding, etc.) one could try to let Perl do the work and use Perl's automagic utf8 conversion:
#!/usr/bin/perl
use strict; use warnings;
use open IO => ':locale';
my $regex = qr/ [[:upper:]] [[:lower:]]+ [[:upper:]] /x;
foreach my $arg (@ARGV) {
$arg.="\x{1234}";chop $arg; # poor man's method
print "Argument: '$arg'; ",utf8::is_utf8($arg)?'':'not ',"utf8\n";
print "Argument in lowercase letters: ",lc($arg),"\n";
print 'Ul+U ',($arg=~m/$regex/)?'':'not ',"found \n";
}


My conclusion
It's ugly, it's a poor man's methode. But it works. Instead of appending an unicode character you can also useutf8::upgrade.
4th Attempt: The best method I found so far
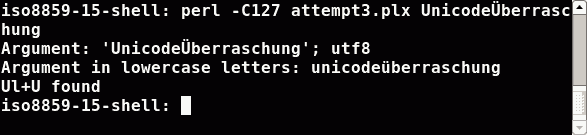
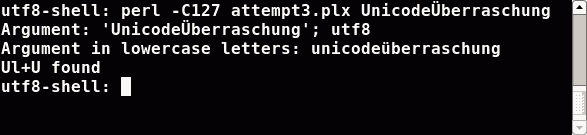
Ok, appending a unicode character to force Perl to convert the string to utf8 encoding and set the internal utf8 flag is bad style. In the case you know that your data comes in either utf8 encoded or in an other encoding you really know, then use Perl's methods to do the conversion and tell Perl exactly what to do:
#!/usr/bin/perl -C127
use strict; use warnings;
use Encode;
use open IO => ':locale';
my $regex = qr/ [[:upper:]] [[:lower:]]+ [[:upper:]] /x;
foreach my $arg (@ARGV) {
$arg=Encode::decode('iso8859-15',$arg) unless utf8::is_utf8($arg);
print "Argument: '$arg'; ",utf8::is_utf8($arg)?'':'not ',"utf8\n";
print "Argument in lowercase letters: ",lc($arg),"\n";
print 'Ul+U ',($arg=~m/$regex/)?'':'not ',"found \n";
}


The hints
- Always tell Perl the encoding of the data coming in. For all open commands use the one with the three arguments and specifiy the encoding.
- Tell Perl with use open IO => ':locale'; to use the right encoding for the output, i.e. tell Perl to look for the shell enviroment variables and use this encoding for default IO.
- If you have unicode strings in your source code, tell Perl in adavance: use utf8;.
- Convert all your input data to unicode as soon as possible, i.e. force Perl to use internally utf8 as soon as possible.
Discussion
Great analysis, Christian. This should help TWiki devs trying to pass UTF8 values to programs that are run un the shell, such as grep and rcs, as well as assisting in a general understanding of how unicode doesn't work in perl. -- CrawfordCurrie - 09 Jun 2008 I think the above effects happen in every case. It doesn't matter if the data is received from command line arguments, files, sockets or STDIN. I've chosen command line arguments above, because one could do easy tests with them. Unicode works in Perl. What's not working well is the one-byte encoding (often chosen by Perl if not stated otherweise). If you've convinced Perl to use utf8 internally, Perl is a powerful unicode-aware tool. -- ChristianLudwig - 09 Jun 2008 Unicode works in Perl. What's not working well is the one-byte encoding tallies perfectly with my own findings on the subject. If any TWiki users were really serious about using international character sets, then they would step up to address UseUTF8. -- CrawfordCurrie - 10 Jun 2008 What are the interactions with the file system of the server's operating system? One of the major problems utf8 is, that twiki uploads an attachment to a wrong directory when the topic has got umlauts in it, even creates new topics when a topic with umlauts in its name is saved again as encodings are encoded again and again. The urls to attachments are pointing to the wrong directory or apache resolves them to the wrong directory on the filesystem. I wished it was only a perl thing that we could resolve. In addition perl has got some other internal problems with utf8. See Bugs:Item5144 showing an example how to segfault perl (mis-)using utf8. -- MichaelDaum - 13 Jun 2008 For test purposes I run a TWiki with Localeen_GB.UTF-8 and charset utf-8. Up to now I haven't seen the attachment problems described above. For exmaple I have a topic TestPageÖÄÜMitUmlauten with an attachment called testβγ.txt and I never got the effects described above. What can I do to reproduce the problem. I tried Firefox with network.standard-url.encode-utf8 true together with network.standard-url.escape-utf8 false and the other way round. In both cases I cannot reproduce this. Sorry.
My proposal with this topic is: Even if your output (in html, on the filesystem, or elsewhere) is only latin1 encoded, write your Perl program in such way that it's always using utf8 internally (because as I tried to show above: Perl works best with when all the strings are encoded to utf8 as soon as possible). My proposal in short: Convert all your input (from the input encoding) to utf8; do the processing and convert all the output data to the output encoding.
In my opinion (please correct me if I'm wrong) if look at TWiki Code I do not know if the strings used in some methods are utf8 or some other encoding. I think there is no clear contract/API stating "We are all doing our processing in utf8, indepently of the input or output encoding". And because of this, I have the feeling that there are a lot of (too much?) lines trying to find out the encoding and trying to do different things.
-- ChristianLudwig - 13 Jun 2008
Good to see some thinking about this. TWiki really does need to support Unicode completely - it isn't that hard to do but there are a lot of details to be worked out.
TWiki doesn't support Unicode at all internally, with the exception of EncodeURLsWithUTF8. There have been some partial attempts in a few areas, which generally break things, and a few years ago I did a lot of hacking to try to get UnicodeSupport working on an old version of TWiki. Some of the issues I ran into: - Performance - may be better now, but back then it did really slow down operations, so work on this is important
- Bugginess of Perl Unicode - again, should be better now, but I ran into some issues
- Interaction with locales - if we are not using Perl locales when in Unicode mode, some other approach needs to be taken to handle national collation orders when sorting. May have changed if some bugs are fixed but I wouldn't bet on it as many Perl Unicode apps don't use locales at all.
- Backward compatibility with Perl 5.6 and early 5.8.x's - once we start doing UnicodeSupport, without some attention and extra work on this, TWiki will no longer work on pre-5.8 versions of Perl (and possibly only on later 5.8 versions - some systems have older 5.8.x's with too many Unicode bugs to be usable) - so it will be important to survey our user base to see how they feel about this. If backward compatibility is seen as important, this will require some extra work - one idea on dynamically supporting both Unicode and non-Unicode mode is in UnicodeSupport.
- Data conversion of topics and filenames - any I18N data in the topics or filenames (including attachment filenames but not contents) will need to be converted if we don't support non-Unicode mode. There are some tools on most Unix systems that will handle this, but this requires an upgrade step, unlike all other TWiki upgrades. Doing this topic by topic as they are written will not work because the older topics won't be viewable properly (unless you have per-topic Unicode mode which is fairly horrible IMO).
- Automating the upgrade process could be quite hairy, particularly the filename changes in a deep directory hierarchy, and would probably not work on MacOS X at all due to MacOSXFilesystemEncodingWithI18N - probably best to ensure the upgrader does good backups and provide some scripts and docs. There might be similar problems on NTFS or FAT filesystems, possibly with variations depending on whether the OS is *nix or Windows - I believe that NTFS translates UTF-8 to UTF-16 but hopefully it doesn't do any UnicodeNormalisation.
 ... TWiki processes everything internally in one charset and it is not usually Unicode because we don't have any real UnicodeSupport yet. Some people have added some special cases and in some cases have broken things. I think it will be hard enough to UseUTF8 throughout the whole of TWiki (files, web clients, email clients and WYSIWYG editors) without also trying to support other charsets at the same time - that can be added later perhaps but if you have Unicode support in your various clients and on the server, why use anything else?
I've done a major update on UseUTF8 and UnderstandingEncodings incidentally.
-- RichardDonkin - 14 Jun 2008
... TWiki processes everything internally in one charset and it is not usually Unicode because we don't have any real UnicodeSupport yet. Some people have added some special cases and in some cases have broken things. I think it will be hard enough to UseUTF8 throughout the whole of TWiki (files, web clients, email clients and WYSIWYG editors) without also trying to support other charsets at the same time - that can be added later perhaps but if you have Unicode support in your various clients and on the server, why use anything else?
I've done a major update on UseUTF8 and UnderstandingEncodings incidentally.
-- RichardDonkin - 14 Jun 2008


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
a1_1_iso885915.png | manage | 2 K | 08 Jun 2008 - 11:56 | ChristianLudwig | |
| |
a1_1_utf8.png | manage | 2 K | 08 Jun 2008 - 11:57 | ChristianLudwig | |
| |
a1_2_iso885915.png | manage | 2 K | 08 Jun 2008 - 11:57 | ChristianLudwig | |
| |
a1_2_utf8.png | manage | 2 K | 08 Jun 2008 - 11:57 | ChristianLudwig | |
| |
a2_iso885915.png | manage | 2 K | 08 Jun 2008 - 11:57 | ChristianLudwig | |
| |
a2_utf8.png | manage | 2 K | 08 Jun 2008 - 11:58 | ChristianLudwig | |
| |
a3_iso885915.png | manage | 2 K | 08 Jun 2008 - 11:58 | ChristianLudwig | |
| |
a3_utf8.png | manage | 2 K | 08 Jun 2008 - 11:58 | ChristianLudwig | |
| |
a4_iso885915.png | manage | 2 K | 08 Jun 2008 - 11:58 | ChristianLudwig | |
| |
a4_utf8.png | manage | 2 K | 08 Jun 2008 - 11:59 | ChristianLudwig | |
| |
attempts.zip | manage | 1 K | 08 Jun 2008 - 11:59 | ChristianLudwig |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r6 < r5 < r4 < r3 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r6 - 17 May 2015, CrawfordCurrie
The copyright of the content on this website is held by the contributing authors, except where stated elsewhere. See Copyright Statement.  Legal Imprint Privacy Policy
Legal Imprint Privacy Policy
Legal Imprint Privacy Policy